The Verifiers Silence
Rule-based verifiers make some criteria visible: correct answer, valid format, passing test. But what they do not score does not disappear. It becomes behavior the system learns without leaving an audit trail.


What rule-based verification leaves to learn
The Concrete Observation
On multilingual prompts, DeepSeek-R1-Zero could begin reasoning in one language and continue in another. The final answer might still be correct. The required structure might still be present. The answer could pass while the reasoning changed languages underneath it.
The DeepSeek-R1 technical report describes the training setup with unusual clarity. DeepSeek-R1-Zero was trained with GRPO using a rule-based reward system. Accuracy rewarded whether the final answer matched the expected solution. Format rewarded whether the thinking process appeared inside the required tags; the training template also placed the final answer inside answer tags so the output could be parsed and checked. No neural reward model participated at this stage.
Language consistency was not part of that reward. The verifier neither rewarded staying in one language nor penalized shifting between languages. That dimension sat outside the initial reward boundary.
The model nevertheless had to generate extended reasoning traces capable of producing a correct answer and satisfying the required format. Accuracy and format supplied active pressure. Language consistency supplied none. The language pattern still had to resolve. It was resolved through whatever continuations remained compatible with the rewards that were present: the base model’s priors, the distribution of multilingual prompts, and the sampling process itself.
DeepSeek later recorded the mixing as a limitation and added an explicit language-consistency reward in the subsequent R1 stage.
The verifier did not penalize language mixing. It simply made language consistency irrelevant to reward.
The Boundary
That is the boundary a verifier draws. It does not only specify what counts. It also specifies what will not be counted.
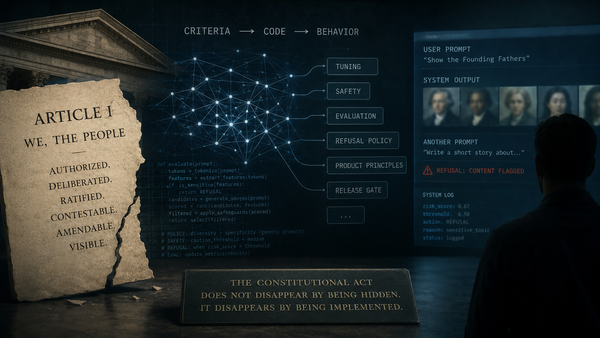
One side of the boundary is visible. Accuracy can be named. Format can be named. Each can be checked, reported, and revised. These terms become legible because the system is trained against them. They appear as reward types. They enter the technical report as explicit criteria. They can later be adjusted when the training run produces behavior the designers no longer want.
The other side is harder to see. Language consistency had no comparable standing. It was not rejected. It was not accepted. It was not made directly reward-relevant.
But unscored dimensions do not disappear. A model cannot answer a prompt without taking on some sequence, style, length, language pattern, and route through the problem. Even when only accuracy and format receive explicit reward, the model still has to generate a trace that gets from prompt to answer. The unchecked dimensions therefore cannot remain null. They are filled by whatever continuations satisfy the checked criteria while remaining compatible with the rest of the training setup.
This is why omission matters without becoming intention. The absence of a language-consistency term did not push the model toward mixed-language reasoning in the manner of an explicit reward. It supplied no counter-pressure on that dimension. So long as the trace still produced a correct answer in the required form, the language pattern inside the reasoning was left to resolve through the rest of the training dynamics.
DeepSeek’s subsequent patch matters, but not because it closes the structure. Once language consistency was added, the boundary did not disappear. It moved. Accuracy, format, and language consistency could now be named. Other dimensions still could not. A verifier can add criteria when an omission becomes visible, but each addition redraws the line between what the reward now knows how to see and what remains outside its field of scoring.
That is why the patch does not dissolve the silence. It proves the system can revise its criteria, not that the space of relevant criteria can be closed. “Add the missing reward term” is a real engineering answer to a discovered failure. It is not an answer to the prior question of which dimensions will become visible only after the model has already learned to behave on them.
The criterion and its absence are seeded by the same decision. Only one of them is ever called a criterion.
The Trap
Rule-based verification appears to solve opacity because the criterion can be inspected as an object rather than inferred from a neural reward model. Accuracy checks whether the final answer is correct. Format checks whether the output appears in the required structure. In code domains the verifier may run tests; in formal domains it may confirm that a proof holds. The terms of judgment stand outside the model as rules that can be named and revised.
DeepSeek-R1-Zero made that structure unusually legible. The initial reward consisted of accuracy and format, applied through GRPO without a neural reward model. The paper also recorded the limitation that appeared during that stage: mixed-language reasoning on multilingual prompts. The subsequent R1 stage added a language-consistency reward. This is design-time transparency. It allows a reader to see what the verifier checked and what it did not make directly reward-relevant.
That transparency does not produce output-level traceability after training. A documented verifier identifies the pressure that was applied. It does not supply a map from any particular generated trace back to the mixture of checked terms, base priors, training dynamics, and dimensions the reward never named. The boundary remains visible in the paper. The output does not show how the boundary trained it.
The clarity of the verifier changes the way the boundary is perceived. When accuracy and format function as deterministic checks, the selected version of correctness begins to read as technical ground truth rather than as one possible boundary among others. The dimensions left outside that boundary — language consistency in this case — then appear as incidental behavior rather than as the other side of the same design decision.
OpenAI’s public documentation of its reasoning models sharpens the point by contrast, but the comparison is asymmetric. DeepSeek supplies a documented verifier structure, a recorded limitation, and a subsequent patch. OpenAI’s public materials describe large-scale reinforcement learning for chain-of-thought reasoning but do not supply an equivalent public breakdown of automated verifier composition. These are not two instances with the same evidentiary weight. They are two disclosure conditions that terminate in the same downstream problem. DeepSeek makes the verifier unusually visible as a design artifact. OpenAI’s public materials leave the verifier composition largely unspecified. Neither condition gives a downstream reader an output-level map back to the training pressures that formed the behavior.
Verifiability at training time does not purchase output-level auditability after training. It can make the verifier legible as a design artifact while leaving its behavioral effects difficult to recover in any particular output.
The Disclosure Objection
DeepSeek’s paper names the reward structure, the training method, the mixed-language limitation, and the subsequent addition of a language-consistency term. This is substantive design-time transparency. It makes the verifier’s initial boundary available for inspection in a way that many training runs do not.
The objection therefore carries weight: if the reward terms were documented, in what sense can the verifier still be described as silent?
The answer is that documentation of the boundary is not traceability of its effects. The paper can state that accuracy and format were rewarded and that language consistency was not. It cannot take a later reasoning trace and assign its features to distinct sources: this came from explicit reward pressure, this from base priors or sampling, this from the dimension the reward never named. Once training pressure has been converted into learned behavior, the original boundary no longer appears as a readable label inside the output.
The stronger objection is not disclosure but repair. If language consistency was missing, add it. If another omission appears, add that too. On this view, the verifier regime is not silent in any troubling sense. It is iterative. It discovers gaps, patches them, and improves.
That objection should not be dismissed. Patch-as-you-go is a real engineering discipline. It is how many systems become useful at all. But the answer assumes that the missing dimensions form a finite set that iteration can exhaust. The verifier gives no such guarantee. Its criteria come from a designed vocabulary: accuracy, format, language consistency, and whatever else the system builders have learned to name. The model’s behavior can vary along dimensions that were not specified by that vocabulary in advance.
A patch can promote one exposed dimension into a criterion. It cannot show that the remaining space has been bounded. The regime learns by naming what its last boundary left unscored, but each naming happens after behavior has already made the omission legible.
Engineers already recognize related problems under names such as reward hacking, specification gaming, and incomplete objectives. Those phenomena are real. The narrower issue here is where that familiar problem becomes harder to see. When the rule is clean, deterministic, and publicly documented, the boundary around the rule becomes easier to treat as settled technical fact rather than as a specific, contestable design decision. The omission recedes from view precisely because the criterion looks obvious.
That is why the disclosed verifier remains silent in the relevant sense. It speaks clearly about what it checks. It says much less about what formed outside its checks.
Documentation of the criterion does not document the behavior formed by everything the criterion left outside itself.
What Governance Inherits
Downstream governance still operates, but it no longer begins with an untouched reasoner. Prompts, policies, red-team reports, monitoring systems, refusal rules, and release gates remain real instruments of constraint. They can still redirect, block, or surface failures. They do not, however, encounter a model whose practical criteria have yet to be shaped by training-time reward boundaries.
In RLVR, machine-checkable standards of success — correct answer, required format, passing test, valid proof — can be made part of the optimization process itself. These standards no longer function only as post-generation checks. They become signals through which the model is shaped before any downstream actor sees an output. By the time a policy team revises a prompt or a red team tests a refusal, some dispositions have already formed under earlier reward pressure.
That inheritance changes what downstream governance can see. A prompt revision or monitoring rule can constrain behavior that has already formed. It cannot recover, in any single trace, how the learned disposition behind that behavior was composed from explicit reward terms, omitted dimensions, base priors, sampling dynamics, and later training. The output arrives as conduct rather than as an annotated record of which pressures produced it.
Downstream governance still acts. It acts on a reasoner already shaped by reward boundaries its visible controls did not draw.
The next missing term can often be added once it becomes visible. The harder question is what it would mean for a verifier regime to know, before training, what it has not yet learned to check.
Source Note
This essay relies primarily on DeepSeek-AI’s technical report, “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.” The report describes DeepSeek-R1-Zero as trained with GRPO using rule-based rewards, mainly accuracy and format rewards, without an outcome or process neural reward model. It also records language mixing as a limitation and describes the later addition of a language-consistency reward during the DeepSeek-R1 training pipeline.
The claim that language consistency sat outside the initial R1-Zero reward boundary is inferred from that documented reward specification and from the subsequent addition of an explicit language-consistency reward. The broader claims about boundaries, omitted dimensions, and output-level traceability are analytic claims built from that sequence rather than claims made by DeepSeek.
The OpenAI comparison is used only as a disclosure contrast. OpenAI’s public materials describe large-scale reinforcement learning for chain-of-thought reasoning, but they do not provide a DeepSeek-style public breakdown of automated verifier composition.