The Failure Archive


How past breakdowns become future standards
A release candidate can look better and still fail.
The public-facing numbers are clean. The model solves more tasks. The coding score has moved in the right direction. The latency is lower. The obvious regressions have been checked. On the external scorecard, the system looks like progress.
Then someone opens the internal trace.
The problem is not that the model failed in some general way. It failed in a way the organization has seen before. It took a tool action after weak evidence. Or cited a source that did not support the claim. Or turned an ambiguous request into a confident recommendation in a domain where confidence itself had already become part of the risk.
Someone recognizes the class before the debate begins.
This is not merely a bad answer. It is the kind of bad answer that once survived review. It is the kind of tool-use error that once forced a permission boundary.
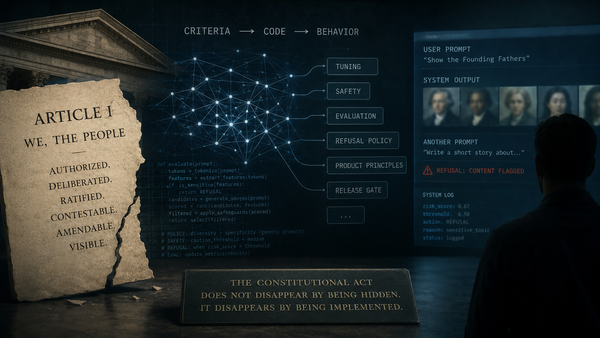
The behavior already has a name. There is a test for it. There is a threshold around it. There is a release criterion attached to it.
From the outside, the new system looks stronger. Inside the organization, strength is not the only question. The archive asks something narrower and harder: has this system reproduced a failure we already learned how to fear?
A benchmark asks what a system can display. A failure archive remembers what an institution has already survived.
The model did not fail because it lacked capability. It failed because it touched a memory.
How Failure Becomes a Standard
A failure does not become a standard simply by being recorded.
At first, it is only an event. A model takes a tool action after weak evidence. It books the wrong appointment, queries the wrong database, sends the wrong instruction, edits the wrong file, or recommends a next step with a confidence the situation did not justify. The trace can show what happened. It can show the prompt, the tool call, the intermediate reasoning, the output, the point where the system crossed from suggestion into action.
But the trace does not yet know what kind of failure it contains.
That judgment has to be made. Was this a tool-use failure, because the model acted before it had enough evidence? Was it a calibration failure, because the model represented uncertainty as confidence? Was it a workflow failure, because the human reviewer was given too little friction before approval? Was it a product-boundary failure, because the system had been allowed to operate too close to consequential action in the first place?
This is why classification is not a neutral administrative step. There is no archivist standing above the organization, calmly placing the failure into its natural category. A safety researcher may see a calibration failure: the system expressed confidence where it should have hesitated. A lawyer may see liability exposure: the product crossed from assistance into delegated action. A product manager may see workflow failure: the interface made review too easy to skip. A domain expert may see context failure: the system missed the one detail that made the action unsafe.
If the failure is classified as calibration, the fix may be an uncertainty threshold. If it is classified as tool-use failure, the fix may be a permission boundary. If it is classified as workflow failure, the fix may be mandatory review. If it is classified as liability exposure, the fix may be a narrower product surface.
The remedy follows the classification. And the classification records which interpretation won.
The internal argument cannot be carried forward in its full form. It has to be compressed into something operational: a regression test, a red-team scenario, a reviewer instruction, an escalation rule, a release checklist item, a permission boundary, a blocking eval.
This compression is lossy, but necessary. The whole debate cannot run again every time a model build is evaluated. The organization cannot relitigate every old incident at every release meeting. So the contested interpretation becomes a rule the system can encounter. The argument becomes a threshold. The concern becomes a test. The judgment becomes a condition of approval.
The archive does not preserve failure as memory alone. It preserves the winning interpretation of failure as a future condition of approval.
Three versions later, the original incident may have faded from view. The names in the room are forgotten. The disagreement that produced the category no longer appears in the interface. What remains is the artifact: the test that fails, the threshold that blocks, the escalation rule that routes, the permission boundary that prevents the action from occurring again.
The organization no longer says, “Remember that incident?”
It says, “This build does not pass.”
Classification is not clerical. It is where failure becomes judgment.
From Record to Standard
The ordinary way to describe this process is simple: organizations remember failures so they do not repeat them.
That is true, but too weak.
An archive does not prevent repetition merely by preserving what happened. It prevents repetition by changing the conditions under which future behavior will be judged. Once a failure has been classified, contested, compressed, and encoded, it no longer belongs only to the past. It becomes part of the machinery that decides whether a future system is allowed to proceed.
The archive first appears retrospective. It seems to look backward: old incidents, old regressions, old red-team findings, old postmortems, old mistakes. But once those records become tests, thresholds, escalation rules, reviewer workflows, release gates, and admissibility criteria, they begin to govern forward.
The archive is not the history of what failed. It is the seed of what will count as failure next time.
That changes the meaning of evaluation. A verifier does not evaluate from nowhere. It inherits cases. The test suite is not checking the present system against a neutral standard. It is carrying forward earlier judgments about which failures mattered. A red-team scenario is not just an adversarial example. It is a remembered breakdown made repeatable. A threshold is not just a number. It is an old argument compressed into a future boundary.
The problem deepens in distributed systems. Where there is no single evaluator visibly applying the archive, criteria can still circulate through the system: what gets escalated, what gets blocked, what counts as uncertainty, what kind of action requires permission, what deviation becomes inadmissible. Some of those criteria may be designed in advance. Others may be inherited from failures that were classified, encoded, and made operational before the system ever encountered the next case.
Later systems meet the archive not as memory but as environment.
The archive is upstream of the evaluator.
Public Scores, Private Memory
The archive becomes most important where public evaluation begins to lose force.
Public benchmarks matter because they are legible. They allow models, labs, products, and releases to be compared against a shared surface. A score can travel. It can appear in a launch post, a procurement conversation, an investor deck, a leaderboard, a policy debate. It gives the outside world something to see.
That visibility is also the weakness.
Once a benchmark becomes important enough, it becomes part of the terrain being optimized. Teams study its distribution. Models are trained around adjacent data. Scaffolds are built around its structure. Leaderboards become targets. What began as a test of capability begins to function as a public interface for capability.
SWE-bench Verified is a clean example. It was designed to measure whether AI systems could solve real software issues. Its strength was its concreteness: real repositories, real issues, real patches, real tests. It became one of the public surfaces on which coding-agent progress could be displayed.
Then the surface began to show its limits. The benchmark did not become useless. Public benchmarks still discipline claims, expose weak systems, and give outsiders a partial view. But SWE-bench Verified became legible.
Some patches passed while failing to resolve the underlying issue. Some tests were too weak to catch the difference. Some tasks became less useful as evidence once the benchmark had become familiar enough to the systems and organizations moving around it.
A public benchmark is useful because it is shared, stable, comparable, and easy to cite. Those same properties make it easier to absorb into the optimization process. The more load-bearing the benchmark becomes, the more its public legibility begins to weaken its evaluative force.
The serious work then moves inward.
The harder questions increasingly require private memory: which failures recurred under deployment pressure, which patches passed the test while missing the issue, which red-team cases exposed behavior the public suite did not contain, which customer incidents forced a boundary the benchmark could not imagine.
This is where the failure archive becomes a different kind of asset. It does not merely contain more examples. It contains remembered breakdowns that have already been interpreted, argued over, compressed, and made operational. It carries knowledge the benchmark never tested for: not just what worked, but what failed in ways the organization learned to recognize.
The institution with the denser archive does not merely know more facts. It has more encoded judgment.
That judgment is difficult to display. It is too contextual for a leaderboard and too operationally specific for a public score. A benchmark can show that a system passed a known test. An archive can remember the class of failure the known test never asked about.
The more public evaluation becomes legible, the more serious evaluation moves into forms that are not.
The Trapdoor
External governance acts on what it can observe.
It can demand benchmark results. It can mandate audits. It can regulate deployment contexts. It can require incident reporting. None of these are trivial.
But they do not automatically reach the body of memory in which the operative standards were formed.
The temptation is to answer with better disclosure requirements. Make the logs public. Require red-team findings. Standardize incident reports. Force companies to publish the failure classes that shaped release decisions.
That answer is reasonable. It is also incomplete.
Disclosure requirements produce records, not archives. The standard is not the log alone. It is the log plus the classification, the internal argument, the workflow that absorbed it, and the authority that made one interpretation binding.
A red-team log is not just a list of prompts that failed. It is a record of how an organization learned to see those failures: which risks mattered, which objections lost, which future behaviors became inadmissible. An incident database is not just raw evidence. It is evidence plus classification, context, institutional memory, domain expertise, release pressure, legal interpretation, product judgment, and local precedent.
Strip away that context to make the archive externally legible, and the archive stops being the same object.
An outside observer may see the record. But the record without the classification is incident data. The classification without the internal argument is a label. The label without the workflow is a compliance artifact. The artifact without the archive is not the standard.
The archive makes the system more governable internally because it carries dense, situated memory of what has gone wrong and how those failures were interpreted. But that same situatedness makes it harder to govern externally. The archive’s value depends on the very context external governance must simplify in order to inspect, compare, and regulate it.
Outside governance does not become impossible. It becomes structurally dependent on what it cannot fully observe.
The outsider is not failing because they cannot see the outputs. They can see the outputs. They can see the benchmark. They can see the model card. They may even see a formal incident report.
What they cannot see is where the operative standard was made.
The standard was made when a failure was classified, argued over, compressed, encoded, and allowed to govern future behavior. It was made in a body of institutional memory that cannot be translated into the forms governance requires without ceasing to be the same object.
That is practical sovereignty: not sovereignty over every output, but sovereignty over the standard by which outputs will be judged.
Failure memory is not retrospective. It is constitutional.
Absolutely. Here is the final clean version assembled as one Ghost-ready draft.
The Failure Archive
How past breakdowns become future standards
A release candidate can look better and still fail.
The public-facing numbers are clean. The model solves more tasks. The coding score has moved in the right direction. The latency is lower. The obvious regressions have been checked. On the external scorecard, the system looks like progress.
Then someone opens the internal trace.
The problem is not that the model failed in some general way. It failed in a way the organization has seen before. It took a tool action after weak evidence. Or cited a source that did not support the claim. Or turned an ambiguous request into a confident recommendation in a domain where confidence itself had already become part of the risk.
Someone recognizes the class before the debate begins.
This is not merely a bad answer. It is the kind of bad answer that once survived review. It is the kind of tool-use error that once forced a permission boundary.
The behavior already has a name. There is a test for it. There is a threshold around it. There is a release criterion attached to it.
From the outside, the new system looks stronger. Inside the organization, strength is not the only question. The archive asks something narrower and harder: has this system reproduced a failure we already learned how to fear?
A benchmark asks what a system can display. A failure archive remembers what an institution has already survived.
The model did not fail because it lacked capability. It failed because it touched a memory.
How Failure Becomes a Standard
A failure does not become a standard simply by being recorded.
At first, it is only an event. A model takes a tool action after weak evidence. It books the wrong appointment, queries the wrong database, sends the wrong instruction, edits the wrong file, or recommends a next step with a confidence the situation did not justify. The trace can show what happened. It can show the prompt, the tool call, the intermediate reasoning, the output, the point where the system crossed from suggestion into action.
But the trace does not yet know what kind of failure it contains.
That judgment has to be made. Was this a tool-use failure, because the model acted before it had enough evidence? Was it a calibration failure, because the model represented uncertainty as confidence? Was it a workflow failure, because the human reviewer was given too little friction before approval? Was it a product-boundary failure, because the system had been allowed to operate too close to consequential action in the first place?
This is why classification is not a neutral administrative step. There is no archivist standing above the organization, calmly placing the failure into its natural category. A safety researcher may see a calibration failure: the system expressed confidence where it should have hesitated. A lawyer may see liability exposure: the product crossed from assistance into delegated action. A product manager may see workflow failure: the interface made review too easy to skip. A domain expert may see context failure: the system missed the one detail that made the action unsafe.
If the failure is classified as calibration, the fix may be an uncertainty threshold. If it is classified as tool-use failure, the fix may be a permission boundary. If it is classified as workflow failure, the fix may be mandatory review. If it is classified as liability exposure, the fix may be a narrower product surface.
The remedy follows the classification. And the classification records which interpretation won.
The internal argument cannot be carried forward in its full form. It has to be compressed into something operational: a regression test, a red-team scenario, a reviewer instruction, an escalation rule, a release checklist item, a permission boundary, a blocking eval.
This compression is lossy, but necessary. The whole debate cannot run again every time a model build is evaluated. The organization cannot relitigate every old incident at every release meeting. So the contested interpretation becomes a rule the system can encounter. The argument becomes a threshold. The concern becomes a test. The judgment becomes a condition of approval.
The archive does not preserve failure as memory alone. It preserves the winning interpretation of failure as a future condition of approval.
Three versions later, the original incident may have faded from view. The names in the room are forgotten. The disagreement that produced the category no longer appears in the interface. What remains is the artifact: the test that fails, the threshold that blocks, the escalation rule that routes, the permission boundary that prevents the action from occurring again.
The organization no longer says, “Remember that incident?”
It says, “This build does not pass.”
Classification is not clerical. It is where failure becomes judgment.
From Record to Standard
The ordinary way to describe this process is simple: organizations remember failures so they do not repeat them.
That is true, but too weak.
An archive does not prevent repetition merely by preserving what happened. It prevents repetition by changing the conditions under which future behavior will be judged. Once a failure has been classified, contested, compressed, and encoded, it no longer belongs only to the past. It becomes part of the machinery that decides whether a future system is allowed to proceed.
The archive first appears retrospective. It seems to look backward: old incidents, old regressions, old red-team findings, old postmortems, old mistakes. But once those records become tests, thresholds, escalation rules, reviewer workflows, release gates, and admissibility criteria, they begin to govern forward.
The archive is not the history of what failed. It is the seed of what will count as failure next time.
That changes the meaning of evaluation. A verifier does not evaluate from nowhere. It inherits cases. The test suite is not checking the present system against a neutral standard. It is carrying forward earlier judgments about which failures mattered. A red-team scenario is not just an adversarial example. It is a remembered breakdown made repeatable. A threshold is not just a number. It is an old argument compressed into a future boundary.
The problem deepens in distributed systems. Where there is no single evaluator visibly applying the archive, criteria can still circulate through the system: what gets escalated, what gets blocked, what counts as uncertainty, what kind of action requires permission, what deviation becomes inadmissible. Some of those criteria may be designed in advance. Others may be inherited from failures that were classified, encoded, and made operational before the system ever encountered the next case.
Later systems meet the archive not as memory but as environment.
The archive is upstream of the evaluator.
Public Scores, Private Memory
The archive becomes most important where public evaluation begins to lose force.
Public benchmarks matter because they are legible. They allow models, labs, products, and releases to be compared against a shared surface. A score can travel. It can appear in a launch post, a procurement conversation, an investor deck, a leaderboard, a policy debate. It gives the outside world something to see.
That visibility is also the weakness.
Once a benchmark becomes important enough, it becomes part of the terrain being optimized. Teams study its distribution. Models are trained around adjacent data. Scaffolds are built around its structure. Leaderboards become targets. What began as a test of capability begins to function as a public interface for capability.
SWE-bench Verified is a clean example. It was designed to measure whether AI systems could solve real software issues. Its strength was its concreteness: real repositories, real issues, real patches, real tests. It became one of the public surfaces on which coding-agent progress could be displayed.
Then the surface began to show its limits. The benchmark did not become useless. Public benchmarks still discipline claims, expose weak systems, and give outsiders a partial view. But SWE-bench Verified became legible.
Some patches passed while failing to resolve the underlying issue. Some tests were too weak to catch the difference. Some tasks became less useful as evidence once the benchmark had become familiar enough to the systems and organizations moving around it.
A public benchmark is useful because it is shared, stable, comparable, and easy to cite. Those same properties make it easier to absorb into the optimization process. The more load-bearing the benchmark becomes, the more its public legibility begins to weaken its evaluative force.
The serious work then moves inward.
The harder questions increasingly require private memory: which failures recurred under deployment pressure, which patches passed the test while missing the issue, which red-team cases exposed behavior the public suite did not contain, which customer incidents forced a boundary the benchmark could not imagine.
This is where the failure archive becomes a different kind of asset. It does not merely contain more examples. It contains remembered breakdowns that have already been interpreted, argued over, compressed, and made operational. It carries knowledge the benchmark never tested for: not just what worked, but what failed in ways the organization learned to recognize.
The institution with the denser archive does not merely know more facts. It has more encoded judgment.
That judgment is difficult to display. It is too contextual for a leaderboard and too operationally specific for a public score. A benchmark can show that a system passed a known test. An archive can remember the class of failure the known test never asked about.
The more public evaluation becomes legible, the more serious evaluation moves into forms that are not.
The Trapdoor
External governance acts on what it can observe.
It can demand benchmark results. It can mandate audits. It can regulate deployment contexts. It can require incident reporting. None of these are trivial.
But they do not automatically reach the body of memory in which the operative standards were formed.
The temptation is to answer with better disclosure requirements. Make the logs public. Require red-team findings. Standardize incident reports. Force companies to publish the failure classes that shaped release decisions.
That answer is reasonable. It is also incomplete.
Disclosure requirements produce records, not archives. The standard is not the log alone. It is the log plus the classification, the internal argument, the workflow that absorbed it, and the authority that made one interpretation binding.
A red-team log is not just a list of prompts that failed. It is a record of how an organization learned to see those failures: which risks mattered, which objections lost, which future behaviors became inadmissible. An incident database is not just raw evidence. It is evidence plus classification, context, institutional memory, domain expertise, release pressure, legal interpretation, product judgment, and local precedent.
Strip away that context to make the archive externally legible, and the archive stops being the same object.
An outside observer may see the record. But the record without the classification is incident data. The classification without the internal argument is a label. The label without the workflow is a compliance artifact. The artifact without the archive is not the standard.
The archive makes the system more governable internally because it carries dense, situated memory of what has gone wrong and how those failures were interpreted. But that same situatedness makes it harder to govern externally. The archive’s value depends on the very context external governance must simplify in order to inspect, compare, and regulate it.
Outside governance does not become impossible. It becomes structurally dependent on what it cannot fully observe.
The outsider is not failing because they cannot see the outputs. They can see the outputs. They can see the benchmark. They can see the model card. They may even see a formal incident report.
What they cannot see is where the operative standard was made.
The standard was made when a failure was classified, argued over, compressed, encoded, and allowed to govern future behavior. It was made in a body of institutional memory that cannot be translated into the forms governance requires without ceasing to be the same object.
That is practical sovereignty: not sovereignty over every output, but sovereignty over the standard by which outputs will be judged.
Failure memory is not retrospective. It is constitutional.
Source notes for the SWE-bench passage: SWE-bench Verified is officially described as a human-filtered subset of 500 instances; OpenAI later argued that SWE-bench Verified had become increasingly contaminated and no longer reflected meaningful real-world software-development improvement; UTBoost reported insufficient tests and erroneous patches affecting SWE-bench evaluations. (SWE-bench)