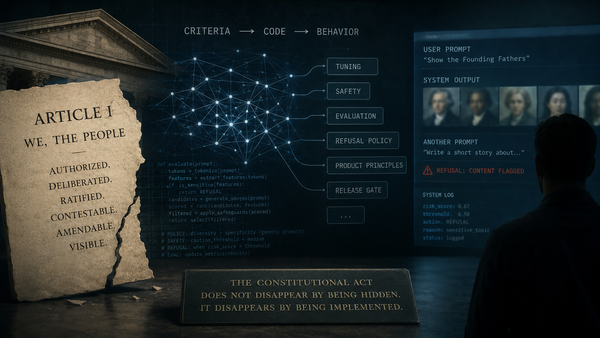
The Record of Oversight


How AI-mediated workflows can preserve evidence of judgment while weakening judgment itself
I. The Pre-Structured Case
A clinician opens a case that has already been summarized.
The symptoms have been organized. The likely diagnosis has been ranked. A risk score sits beside the recommendation. The next step has been suggested, the escalation status marked, the note partially drafted. Nothing about the interface says the human has been removed. On the contrary, the workflow is waiting for a human act: review, approve, modify, sign.
But the case has not arrived untouched.
By the time it reaches the clinician, it has already passed through a layer of interpretation. Some details have been elevated. Others have been compressed. The relevant categories have begun to form before the physician has had to form them. What the interface does not show is the case before it knew what it was: the symptom before it became evidence for a ranked diagnosis, the irregular detail before it became noise, the uncertainty before it was translated into a score.
The system has not made the final decision, but it has shaped the field in which the decision will be made.
This is the problem hidden inside the reassurance of “human in the loop.” The phrase tells us that a person remains somewhere in the workflow, but not where that person enters the act of judgment. A human may still review the output, approve the recommendation, or carry responsibility for the result while encountering the case only after the system has already made it legible.
That distinction matters because institutions are increasingly asked to trust AI-mediated systems on the condition that humans remain available as safeguards. A model may draft, summarize, rank, recommend, route, or flag, while a person remains responsible for review. The structure appears reassuring. The system accelerates the routine case. The human catches the exception. Oversight survives.
But this picture assumes the very thing it needs to prove.
It assumes that the human checkpoint still carries the competence that made the checkpoint meaningful in the first place. It assumes that a clinician who mostly sees pre-structured recommendations still retains the practiced ability to notice when the structuring itself is wrong. It assumes that a reviewer trained by thousands of ordinary confirmations will still be able to recognize the one case whose danger lies precisely in looking ordinary.
The harder question is what happens to judgment when the ordinary conditions for practicing judgment have changed. In many institutional settings, humans will remain present for a long time because institutions still need a human surface: someone to review, someone to sign, someone to remain formally authorized to disagree.
But a human can be inside the workflow and still enter too late. A human can retain responsibility while losing contact with the unresolved case. A human can be granted authority to interrupt while being trained, day after day, into the habits of confirmation.
A checkpoint is not a competence.
II. The Wrong Reassurance
The phrase “human in the loop” answers the easiest question.
It tells us that a person remains somewhere inside the workflow: present, named, formally responsible.
But presence is not the same as judgment.
The phrase survives because it satisfies an institutional need. It lets organizations adopt systems that shape consequential decisions without appearing to surrender authority to them. The machine handles scale; the professional preserves accountability.
The picture is not false. It is just too shallow.
A human checkpoint can mean very different things depending on where it sits in the process. It may mean a professional still encounters the case before the system has framed it. It may mean the professional sees the model’s recommendation alongside the underlying materials. It may mean the professional reviews only a summary, a score, a ranked option, or a prefilled conclusion. Each arrangement can be described as human oversight. They do not preserve the same kind of judgment.
That difference matters because oversight is often treated as if it were a stable property. Add a human reviewer and the system becomes safer. Add escalation and the system becomes governable. Add audit logs and the system becomes accountable. But these safeguards can quietly shift from practices of judgment into records of procedure.
Knowing when to disagree is itself a competence. The workflow can record the opportunity without preserving the capacity.
The usual language of automation bias does not fully capture this. Automation bias describes a familiar failure: a person over-trusts a system, accepts a recommendation too easily, or fails to notice an error because the machine appears confident. That problem is real. But it still imagines the failure as an event: the moment when a human trusted the system more than they should have.
The deeper problem is slower.
Judgment atrophy, in this sense, is not the disappearance of intelligence or diligence. It is the loss of practiced contact with the conditions under which interruption becomes possible.
The early evidence points in that direction. In a Microsoft and Carnegie Mellon study of 319 knowledge workers, confidence in generative AI was associated with less critical-thinking effort, while confidence in one’s own judgment was associated with more. The result does not prove institutional atrophy. It shows the direction in which the pressure runs.
It is not only that a person may trust the system in a particular case. It is that the institution may reorganize work so that the human gradually loses contact with the form of judgment the system is supposed to preserve. A clinician who repeatedly reviews pre-structured recommendations does not only save time. She also learns, through repetition, what the workflow treats as salient, what it treats as routine, and what kinds of disagreement appear worth the cost.
Over time, the human role becomes less a site of independent judgment and more a site of confirmation, correction, and exception handling.
That is not the same as being removed from the loop. It may be more difficult to notice because nothing about the workflow announces it. The human remains visible. The review step remains intact. The institution can point to the checkpoint and say that judgment has not been surrendered.
But the question is not whether the workflow contains a human. The question is whether the workflow still maintains the kind of human competence its own safety story depends on.
Automation bias is an error of trust. Judgment atrophy is a failure of maintenance.
III. Judgment Before Category
Maintenance is the right word because judgment is not simply something a professional possesses. It is something kept alive by use.
A clinician does not learn diagnosis only by memorizing diseases. She learns it by repeatedly meeting cases before they have settled into a name. A symptom appears too early, too faintly, or in the wrong combination. A patient describes something that does not quite fit the chart. A lab result looks ordinary until it is placed beside a detail that should not matter but does. The work begins before the diagnosis has become available as a category. It begins in the unstable interval where the case is still becoming intelligible.
That interval matters.
It is where the practitioner learns to notice shape before label: the irregularity that should not be ignored, the pattern that is almost but not quite routine, the false reassurance of a familiar presentation, the detail that interrupts the obvious explanation. This kind of judgment is not reducible to rule-following, and it is not the same as possessing domain knowledge in the abstract. It is the practiced ability to hold a case in its particularity before a category absorbs it.
AI-mediated workflows often enter before that moment is finished.
They summarize the encounter, rank the possibilities, assign risk, mark escalation status, suggest next steps, and translate ambiguity into a form that can move through the organization. That can be useful. Often it will be useful. Institutions do not adopt these systems because they fail at everything. They adopt them because they make work faster, more consistent, more legible, and easier to route.
But that usefulness changes the site of judgment.
When the human encounters the case after it has been summarized, scored, and ranked, the task is no longer the same. The practitioner is not simply judging the case. She is judging a case that has already been partially judged. The question before her is no longer only “What is happening here?” It is also “Is this representation of what is happening trustworthy enough to proceed?”
Those are related capacities. They are not the same act.
The distinction would matter less if practitioners could simply keep both forms of competence equally alive: the old capacity to meet the unresolved case, and the new capacity to assess the system’s representation of it. In principle, they can. But institutions do not preserve skills by wishing to preserve them. They preserve them by making room for their exercise.
Competence follows contact.
That is where divergence becomes decay. The AI-mediated workflow does not merely add a layer on top of ordinary judgment. It can crowd out the conditions under which ordinary judgment is practiced. The raw case appears less often. The unscored case becomes exceptional. The recommendation arrives earlier. The summary becomes the starting point. The professional still works, still reviews, still decides, but the repeated object of attention has changed.
There is already evidence that this concern is not merely speculative. In a 2025 multicenter observational study of colonoscopy, researchers compared standard, non-AI-assisted procedures before and after endoscopists were exposed to AI tools. After AI implementation, the adenoma detection rate in non-AI-assisted colonoscopies fell from 28.4% to 22.4%, an absolute decline of six percentage points; the authors concluded that continuous AI exposure might reduce standard non-AI-assisted performance, suggesting a negative effect on endoscopist behavior.
The issue is not only that AI helps while present. It is what repeated AI assistance may do to the professional act when the assistance is absent, uncertain, wrong, or unavailable. The skill at risk is not abstract intelligence. It is trained perception under conditions where the system has not already marked what deserves attention.
A professional who repeatedly meets unresolved cases practices one kind of attention. A professional who repeatedly reviews structured recommendations practices another. The first learns to form the category. The second learns to assess the category already offered. The second skill is real. It may even become indispensable. But it does not automatically preserve the first.
This is where institutional judgment begins to narrow without announcing itself. Nothing dramatic has to happen. No one has to ban independent thought. The institution only has to make the pre-structured case the ordinary object of review. The practitioner adapts to the object the workflow repeatedly presents.
From outside, review still looks like judgment. The clinician still reads. The recommendation is still checked. The human remains accountable. But the workflow has changed what competence means without changing what competence is called. It has made a different kind of attention normal, then preserved the old language for the new act.
That is the institutional danger. Judgment does not vanish all at once. It is renamed while its conditions of maintenance are quietly crowded out.
IV. The Loop Trains the Supervisor
Crowding out is only half the mechanism.
The workflow does not merely reduce contact with the unresolved case. It forms another kind of competence in its place: fluency with the system’s representation of the domain. The reviewer learns the score, the summary, the alert, the escalation pattern, the ordinary shape of machine-prepared judgment. Something is lost, but something is also built.
The institution thinks it has placed a human over the system.
That is only partly true. The human may review the output, approve the recommendation, correct the note, override the alert, or escalate the exception. But the system is also placing the human inside a repeated environment of attention. It is teaching, by recurrence, what normally matters.
A system only has to present cases in the same structured form often enough. The summary comes first. The score sits beside it. The recommendation arrives with the evidence already arranged around it. The interface marks some details as salient and lets others recede. Over time, the human learns not only from the domain, but from the way the domain is repeatedly displayed.
The loop becomes a curriculum.
It teaches which signals usually matter, which warnings are noise, which scores deserve trust, which categories deserve attention, which deviations are worth the cost of disagreement. This instruction is not explicit. It arrives through repetition. Every ordinary confirmation teaches the reviewer what ordinary looks like. Every accepted recommendation strengthens the background sense of what a good recommendation feels like. Every uneventful approval makes the workflow slightly harder to see as an interpretation rather than a neutral path through the work.
The danger is not that the system commands the human. It is that the system gives the human a world in which some forms of attention are easier to sustain than others. Independent judgment does not need to be forbidden if the workflow makes it slower, more awkward, less rewarded, and less often practiced. Over time, the human learns what the institution asks her to repeat.
This is how the narrowing becomes difficult to see. The habituated reviewer does not look incompetent from outside. She may escalate appropriately, catch obvious errors, correct bad summaries, reject weak recommendations, and operate fluently inside the system. The institution sees that fluency and reads it as preserved judgment. What it cannot easily see is that the fluency has been calibrated to the workflow’s representation of the domain, not necessarily to the domain in its unresolved form.
In routine cases, those two forms of competence can look identical. The reviewer trained by the loop and the reviewer still practiced in independent judgment may both approve the same recommendation, sign the same note, or let the same classification proceed. The difference appears only when the representation itself is wrong: when the score has made the wrong detail salient, when the summary has compressed the exception, when the recommendation has organized the evidence around the wrong category. That is precisely the moment the institution most needs the older competence. It is also the moment least visible in ordinary performance metrics.
The institution may call this experience. In one sense, it is. But it is experience with the workflow’s representation of the domain, not necessarily with the domain before the workflow has made it legible. The reviewer becomes skilled at the environment that now defines competence, and the environment then offers that skill back to the institution as proof that judgment has been preserved.
The human trains the system once; the system trains the human every day.
V. The Wrong Analogy
The obvious objection is that tools have always changed what people know how to do.
Calculators changed arithmetic. GPS changed navigation. Autopilot changed flying. Search engines changed memory. Spellcheck changed writing. Every serious tool rearranges skill. Some forms of competence fade because they no longer need to be exercised in the same way. That is not automatically decay.
This objection is worth taking seriously because the alternative is nostalgia disguised as analysis. No institution should preserve every old skill simply because it once mattered. The question is not whether AI changes human competence. Of course it does. The question is what kind of competence changes, whether the institution still depends on it, and whether the new competence can actually substitute for the old one when failure arrives.
Many earlier tools offloaded execution while leaving the human in contact with the structure of the problem. A calculator performs arithmetic, but it does not decide what mathematical problem is being asked. GPS computes a route, but it does not usually decide what the journey is for. Autopilot can stabilize flight, but the pilot is still trained to understand the aircraft’s situation when automation fails. Aviation has lived with this problem for decades. Automation can make ordinary flight safer while still raising the harder question of what happens to manual proficiency when automation fails. In each case, the tool may change the distribution of labor, but the human can remain in contact with the underlying structure the tool assists.
AI-mediated workflows often move closer to the point where the problem first becomes intelligible. They do not merely accelerate a known operation. They summarize the situation, classify the case, rank possible meanings, decide what evidence is salient, and offer a representation of the problem before the human has fully formed one. The tool does not simply help answer the question. It helps decide what kind of question the case appears to be.
That is where the analogy starts to break.
When execution is offloaded, the human may still practice the prior act of framing. When interpretation is offloaded, the human increasingly begins from a frame already supplied. The loss is not merely manual fluency or procedural memory. It is contact with the unstable moment before the case has been made orderly enough to manage.
Reviewing AI output is a real competence. Knowing when to trust a recommendation, inspect the source, escalate, override, discount a confidence score, or treat an answer as plausible but unsupported will matter more, not less, as AI systems become ordinary infrastructure.
The issue is not whether the new representation is often better. It may be. The issue is whether the institution still relies on a human capacity that the new representation makes less available.
A new competence does not automatically preserve the old one. A lawyer can become efficient at checking generated summaries while reading fewer sources before the summary exists. That efficiency may be real. It may even be institutionally valuable. But it is not the same as repeatedly forming judgment from the underlying materials before the summary has framed what matters.
The issue is not that tools change skills. The issue is when institutions continue to rely on a skill after reorganizing work in ways that make the skill harder to maintain.
That is where the safety story begins to fracture. The institution may still treat human judgment as the backstop because that was true when the workflow was designed, adopted, or justified. But the workflow can erode the competence the safety story presupposes while still producing performances that look competent from the outside. The liability is hidden because the institution has not lost the checkpoint. It has changed the conditions under which the checkpoint is supposed to mean something.
The dangerous loss is not execution after judgment, but contact before judgment.
VI. When Many Eyes Learn the Same Blindness
If one practitioner adapts to the workflow, the effect may remain local. But when many practitioners adapt to the same workflow, the institution begins to see through a common representation.
The same summaries shape first impressions. The same scores organize urgency. The same categories define what counts as routine. The same escalation rules determine what rises into attention. And the same interface teaches many people what disagreement is supposed to look like.
This does not make everyone equally blind. Institutions are never that uniform. Some people will resist the frame. Some will reconstruct the underlying case. Some will notice when the summary has smoothed over the exception. Professional memory does not vanish simply because a tool arrives. But institutional vulnerability does not require universal incompetence. It only requires enough shared narrowing that the organization becomes worse at recognizing the failures its workflow is least able to describe.
Here the evidence changes level. The clearest signs appear first in practitioners: knowledge workers reporting reduced critical effort, endoscopists whose unaided performance may decline after AI exposure, professionals whose review practices shift once assistance becomes ordinary. The institutional claim is narrower and harder. It is not that every organization has crossed this threshold. It is that when many people are trained by the same workflow, individual changes in attention can become shared conditions of organizational perception.
The danger is correlation.
If different practitioners retain different habits of attention, one person’s blind spot can be corrected by another’s. The institution benefits from friction: disagreement between roles, review from different angles, memory held in different places. But if the same system trains many reviewers into the same posture, the institution loses some of that internal difference. The second reviewer may no longer be a true second look. The escalation may no longer move the case into another form of judgment. It may only move the same representation upward.
That is how individual adaptation becomes institutional vulnerability. The institution does not merely contain people who rely on the system. It becomes an organization whose routines, records, and review practices have been calibrated around the system’s way of making cases visible. The narrowing is no longer only cognitive. It is organizational.
From outside, this may look like maturity. The workflow is consistent. Reviewers know how to use it. Escalations are standardized. Fewer cases fall between roles. The organization appears to have moved from improvised adoption to stable incorporation. In one sense, it has. But standardization can hide a loss of independent angles. The institution may have become more coordinated while becoming less capable of surprise.
That misrecognition is not accidental. The institution often measures the health of the workflow by the very signs the workflow is designed to produce: consistency, speed, completion, routing accuracy, escalation compliance, reviewer fluency. But those measures cannot easily reveal whether the organization still possesses forms of judgment that no longer appear in ordinary use. The workflow teaches people how to see, then offers their coordinated performance as evidence that the seeing has been preserved.
At that point, judgment atrophy is no longer only a matter of individual skill. It has become a property of the review ecology. The institution still has many eyes, but the eyes have learned the same way of seeing.
This is the third-order problem. The institution’s instruments for detecting judgment atrophy are themselves increasingly products of the workflow that may be producing it. The same system that narrows attention also defines competent participation, records that participation, and offers the resulting record as evidence of health. The institution does not merely risk losing judgment. It risks losing the ability to distinguish preserved judgment from the workflow’s own signs of successful operation.
The loss remains invisible until the case arrives that the workflow was not built to describe.
VII. Responsibility Survives Competence
When the case arrives that the workflow was not built to describe, the institution still has an answer.
A human was there.
Someone reviewed the recommendation. Someone had authority to disagree. Someone could have opened the underlying materials, questioned the summary, overridden the alert, escalated the exception, or refused the default. The institution has not surrendered responsibility to the system. It has preserved a human checkpoint.
That is the reassurance. It is also the trap.
The human remains inside AI-mediated workflows because institutions need a place where accountability can land. Hospitals need clinicians who can sign. Law firms need lawyers who can file. The filing still bears the lawyer’s name even when the representation beneath it has been machine-shaped. Agencies need officials who can certify. The system may draft, rank, recommend, flag, score, or route, but the institution still needs a responsible surface: someone whose act can convert machine-shaped output into an organizational decision.
In ordinary cases, this arrangement can work well enough. The recommendation is plausible. The summary captures the relevant facts. The risk score tracks what experienced judgment would have noticed anyway. The reviewer confirms, corrects a minor issue, or escalates a case that obviously deserves attention. The institution sees the human checkpoint functioning and has little reason to ask whether the competence behind it is changing.
The difficulty appears when failure depends on the difference between formal authority and practiced judgment.
Formal authority means the reviewer may disagree. Practiced judgment means the reviewer still knows when disagreement is necessary. Formal authority means the clinician can override the system. Practiced judgment means she can recognize the case whose danger lies in being misdescribed by the system. Formal authority means the lawyer is responsible for the filing. Practiced judgment means he can tell when the generated account has made the wrong source, the wrong distinction, or the wrong omission look harmless.
The workflow can preserve the first while eroding the second.
The system organizes attention, but the human remains accountable for what attention failed to notice.
That is the strange division of labor. The system shapes the case. The human authorizes the shaped case. The workflow narrows the encounter, but the institution preserves the human as proof that narrowing has not become surrender.
A person can be answerable for a decision without having been positioned to exercise the judgment that accountability assumes. That is not a contradiction inside the workflow. It is often how the workflow becomes institutionally acceptable. The system does not replace the professional. It places the professional at the point where acceptance, modification, escalation, or refusal can be recorded as a human act.
That recording matters because the human checkpoint does two jobs at once. Operationally, it catches some errors and authorizes routine flow. Institutionally, it reassures the organization that judgment remains present. Legally or publicly, it helps maintain the claim that decisions have not been abandoned to automation. The same human act that may sometimes function as real oversight can also function as evidence that oversight exists.
This is where the checkpoint begins to validate itself. The workflow produces a human act: review, approval, correction, escalation, signoff. The institution records that act as evidence of oversight. That record reduces pressure to ask whether the conditions of oversight have changed. The human presence becomes proof that judgment remains in the process, even when the process has altered what the human is able to judge.
The question quietly shifts. Not: what conditions does this person need in order to judge well? But: was there a person in the process? Not: did the reviewer encounter the case in a form that allowed meaningful disagreement? But: was the reviewer given an opportunity to disagree? Not: is competence being maintained? But: can responsibility be documented?
This is how responsibility can outlive competence without looking like abandonment. The institution does not remove the human. It keeps the human exactly where the governance diagram needs one to appear: after the system has structured the case, before the organization commits to the decision, at the point where approval can be recorded.
The institution keeps the human where blame can land, not necessarily where judgment can still operate.
VIII. The Audit Trail Becomes the Alibi
Once responsibility has been placed, the institution can produce a record.
The case was reviewed. The recommendation was acknowledged. The escalation path was available. The reviewer had authority to disagree. The signoff was captured. The decision did not pass through the system untouched. A human act appears in the chain.
From a distance, that looks like oversight.
And often the record matters. Audit trails do real institutional work. They reconstruct decisions, reveal missing steps, assign responsibility, expose procedural failures, and make consequential systems legible to managers, lawyers, regulators, and internal governance teams. In the cases they were designed to catch, they can be indispensable. A missing signature, a skipped review, a failed escalation, a recommendation accepted without required authorization — these are real failures, and records can show them.
The problem is that judgment decay does not necessarily appear as a missing step.
The trail may be complete. The reviewer may have acted. The signoff may be valid. The escalation path may have existed. The workflow may have done exactly what it was designed to do. The narrowing happens inside the acts the record captures, not between them.
That is the trap hidden inside procedural evidence. The audit trail does not simply document oversight from outside. It documents oversight in the terms the workflow has already defined. If review has come to mean checking a summary, acknowledging a score, confirming a recommendation, or escalating what the interface has marked as exceptional, then the record can faithfully show that review occurred while concealing how narrow review has become.
The institution may believe it is asking whether judgment happened.
The workflow answers with completed steps.
Those are not the same answer.
The deeper problem is that, over time, the difference becomes harder to see. The workflow teaches reviewers what competent participation looks like, then records their participation as evidence of competence. It defines the act, elicits the act, captures the act, and returns the captured act to the institution as proof that judgment remains in the system.
The record can be accurate and still misleading. It can faithfully document the performance of a narrowed role while preserving the older name for that role. Review is still called review. Oversight is still called oversight. The human checkpoint still appears where the governance diagram says it should appear. Nothing has to be falsified for the record to become reassuring in precisely the wrong way.
It can show that the note was signed without showing whether the summary had already organized the patient into the wrong category. It can show that the lawyer checked the citation without showing whether the argument had already been shaped around a missing distinction.
The audit trail captures the workflow’s idea of judgment.
That is the re-entry problem. The institution tries to verify that judgment remains in the loop by consulting the records produced by the loop. But those records have already been shaped by the same workflow that narrowed the conditions of judgment. The apparatus that produces the possible decay also produces the evidence that oversight is functioning. If the institution responds by demanding more procedural evidence, it may deepen the substitution: more records of review, more proof of opportunity, more documentation that the narrowed act occurred.
At that point, the institution does not merely rely on a bad proxy. It begins to inherit the proxy’s definition of the thing itself. Review becomes what the workflow records as review. Oversight becomes what the workflow can show as oversight.
Competence becomes fluency inside the process that now defines competent participation.
The danger is not that the record says nothing. The danger is that it says exactly what the institution has learned to ask for: a completed review, a visible checkpoint, a documented opportunity to disagree, a human name in the sequence.
And once that happens, the problem becomes difficult to answer from inside the same apparatus. An institution that worries its audit trail has become a substitute for judgment will naturally ask for evidence that judgment is being maintained. But the easiest evidence to produce is another record: another checklist, another review protocol, another attestation, another documented opportunity for human disagreement.
The institution tries to verify that oversight is real by making oversight more documentable. That is the trap. The available remedy repeats the disease.
IX. The Exception No One Remembers How to See
The failure that matters most may not look like a failure.
It may arrive as a plausible recommendation, a clean summary, a moderate risk score, a routine triage decision, a note that reads well enough to sign. Nothing in the workflow necessarily breaks. The case moves. The reviewer reviews. The checkpoint is reached. The record is produced.
But the exception has already been made ordinary.
Before the workflow became ordinary, the practitioner might have met the case in a less settled form. A symptom would remain awkward for longer. A detail would drag against the obvious explanation. A source would have to be read before it could be made useful. The case would resist the category because no category had yet been supplied with enough confidence to absorb it.
That resistance is where interruption begins.
The reviewer has to feel the drag of the unresolved detail before she can resist the category that has absorbed it. She has to notice that the ordinary-looking case became ordinary too quickly. She has to sense that the representation is not merely incomplete, but organized around the wrong center.
That is what makes this form of failure different from ordinary system error. The institution is not confronting a broken process. It is confronting a process that has worked according to its own terms while making the wrong case look ready to handle.
Human institutions missed exceptions long before AI entered their workflows. Professionals overlooked symptoms, misread sources, over-trusted templates, and normalized warnings they should have treated as strange. Nor is it obvious that an AI-mediated workflow will be worse on net. It may reduce many ordinary errors, make routine decisions more consistent, and catch patterns people used to miss.
The problem is not simply the rate of error. It is the kind of error that becomes harder to detect.
Ordinary errors can often be noticed as errors within the workflow. A missing field, a skipped review, a recommendation that contradicts a known rule, a score that obviously fails against visible evidence — these are failures the process can be designed to catch. But the exception made ordinary does not present itself as a breakdown. It presents as a completed case. Its danger lies in the fact that the workflow’s signs of success are also the conditions of its concealment.
The patient’s complaint is still in the record, but the summary has made it sound secondary. The risk classification is still visible, but the circumstances that make it dangerous sit outside the fields the workflow treats as important. In both cases, the problem is not that the information has disappeared. It is that the representation has lowered the cost of not noticing what the information means.
These are failures of contact, not failures of presence.
A human may be present for all of them. She may read the summary, consider the score, review the recommendation, and approve the next step. She may do exactly what the institution has asked her to do. What has changed is the relation between the human and the unresolved case. The detail that once would have slowed judgment has been made available without being made disruptive.
That is why the exception can travel so far. Each step confirms that the process is working. The summary is reviewed. The score is considered. The recommendation is accepted or lightly modified. The audit trail fills in behind the decision. If the case later fails, the institution can reconstruct what happened. It can show who touched the decision, when the review occurred, what the system recommended, and whether the escalation path existed.
What it may not be able to reconstruct is the competence that should have interrupted the sequence before the record became complete.
The exception no one remembers how to see does not announce itself as the failure of automation. It arrives as the success of the workflow. It is processed, reviewed, documented, and carried forward by the very signs that tell the institution oversight remains intact.
That is the deeper danger. The institution’s safety story is calibrated to failures that appear as failures: missed reviews, absent humans, skipped escalations, unauthorized decisions, broken procedures. But the failure now approaching may not take that form. It may arrive as a case successfully routed through every safeguard while the one judgment those safeguards depended on has already been trained out of view.
The institution is ready for a failure that violates the workflow. It is less ready for a failure the workflow makes normal.
X. What the Record Cannot Show
The answer is not to abandon records.
Institutions need audit trails, escalation logs, signed reviews, documented overrides, and evidence that consequential decisions did not pass through the system untouched. Without them, failure becomes harder to reconstruct and responsibility becomes easier to evade. The problem is not that records exist. The problem is what institutions may learn to treat them as proof of.
A record can show that the workflow was followed, that a human checkpoint was reached, and that an opportunity to disagree existed. It can show that a decision was reviewed, modified, escalated, or approved.
What it cannot show, by itself, is whether judgment was still alive at the point where the record was made.
Oversight is not preserved by being recorded. It is preserved by maintaining the conditions under which interruption remains possible.
To know whether those conditions are being maintained, the questions themselves are not difficult to name. Can reviewers reconstruct the problem before seeing the recommendation? Can they still notice the detail the summary made secondary? More basically, can the institution still recover the unresolved case from beneath the system’s representation of it?
But those questions do not simply ask for better measurement. They ask the institution to treat its own smooth operation as potentially suspect. That is the harder demand. The institution has learned to read completed reviews, clean escalations, consistent routing, and fluent participation as signs that oversight is working. To test whether judgment remains alive, it would have to ask whether those same signs are also evidence that judgment has been narrowed.
That is why the tests are structurally difficult, not merely inconvenient. They do not just slow the workflow down. They challenge the evidence base on which the workflow’s safety story rests. They create cases where the system’s framing is withheld, interrupted, or treated as provisional. They make competence visible by making smoothness doubtful.
An institution can do that only if it first becomes willing to suspect the smooth operation it has learned to read as health. It has to look at documented human involvement and ask whether involvement still means what the institution needs it to mean.
That suspicion is not easy to generate from inside the same workflow that trained it away.
For any institution adopting these systems, the hard question is not whether the workflow looks governed. It is whether the institution can still distrust the evidence by which it proves that governance to itself.
What would have to disturb a smooth process before the institution wanted to know whether judgment still lived inside it?