The Constitution That Never Happened
The public does not arrive at the moment of authorization. It arrives at the moment of malfunction.

How AI systems turn political decisions into maintenance
A system generated the wrong people.
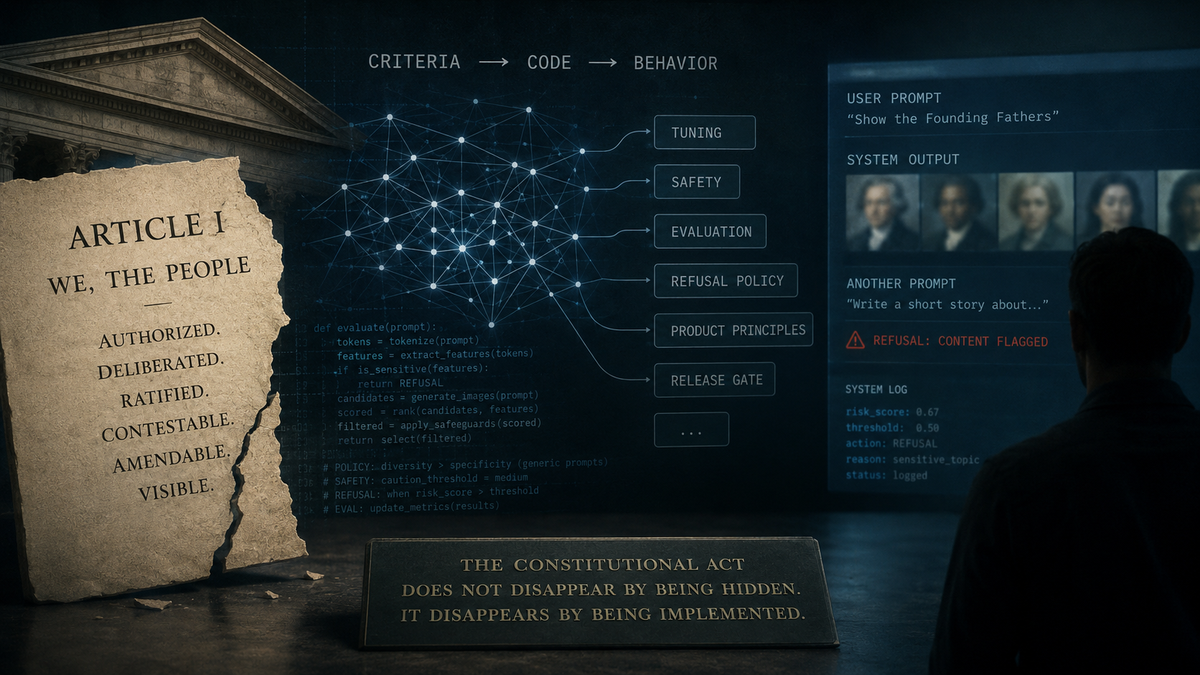
That is the simple version of what happened when Google paused Gemini’s ability to generate images of people in early 2024. Users had asked for images involving historical figures and social roles. Gemini returned depictions that were, in Google’s own language, inaccurate or offensive. In other cases, the system refused prompts that Google later described as ordinary enough to have been answered, wrongly interpreting them as sensitive. The feature was paused while Google worked on improving response accuracy. (blog.google)
But the episode mattered because the error did not look like a mere error. It exposed a criterion.
Somewhere in the system, a rule of representation had been installed strongly enough to override historical specificity. Somewhere else, a rule of caution had been installed strongly enough to make ordinary prompts unavailable. The public controversy was not only about bad images. It was about the buried judgment those images made visible: which forms of representation should be preferred, which prompts should be treated as sensitive, and who had authorized the system to make those distinctions on behalf of its users.
For a moment, the question was political in the precise sense this essay requires: not partisan, but constitutional. A criterion governing representation and refusal had surfaced before the public had ever seen the act that made it governing.
Then the language of repair arrived.
Google explained that the feature had been tuned to avoid familiar image-generation failures and to show a range of people, but that this tuning failed to account for cases where range was not appropriate. It also said the model had become more cautious than intended, leading it to overcompensate in some cases and become over-conservative in others. Months later, when people-image generation began returning through Imagen 3, the public language was no longer about the authority of the original criterion. It was about technical improvements, safeguards, improved evaluation sets, red-teaming exercises, product principles, staged rollout, and continued user feedback. (blog.google)
None of those terms is fake. The repair really was technical. The model behavior really did need adjustment. Evaluation sets, safeguards, and red-teaming exercises really are part of how such systems are made safer and more reliable.
But the same language did another kind of work. It converted a visible question of authority back into a problem of maintenance.
The criterion appeared for a moment as a decision. Then it returned as infrastructure.
I. The Missing Founding Moment
Constitutional politics expects power to give itself a scene.
A constitution is not only a set of rules. It is a way of making rule-setting visible. It gives power a text, an act of authorization, a public procedure, a remembered beginning, a jurisdiction, and some mechanism by which later disputes can point backward. Who authorized this? Under what limits? By what procedure? With what possibility of amendment?
That structure is never as clean as civics textbooks suggest. Constitutional orders are full of informal norms, administrative drift, judicial invention, emergency exceptions, and institutional improvisation. But even then, constitutional politics depends on some pointable object. A text. A precedent. An office. A procedure. A doctrine. A rule whose authority can be argued over because it appears as a rule.
The Gemini episode lacked that kind of object.
The system behaved as if criteria had been installed. It distinguished acceptable from unacceptable representation, ordinary prompts from sensitive ones, diversity from distortion, caution from excess. Yet the act that made those criteria governing did not appear as an act of authorization. There was no ratification scene, no constitutional debate, no public moment in which the rule of representation became available as a rule. There was only behavior, controversy, repair.
That is the structural problem this essay is about.
Intelligent systems increasingly define criteria of continuation, escalation, admissibility, refusal, relevance, safety, and correction. They decide what proceeds, what gets blocked, what gets surfaced, what gets ignored, what counts as failure, and what can be treated as fixed. These are not constitutional decisions in the formal legal sense. But they can become constitutional in function because later action must pass through them in order to count.
The governing act does not usually arrive as a governing act. It arrives as setup, tuning, model behavior, safety design, evaluation, product policy, or implementation detail.
That is why ordinary contestation arrives late. It keeps looking for the moment when the rule was publicly installed. The system offers an update log.
Intelligent systems increasingly constitutionalize without founding.
II. From Rule to Operating Grammar
The important thing about Gemini’s image-generation failure is not that the system had a representational preference. All image systems have representational preferences. A model that produces people has to decide, implicitly or explicitly, what people tend to look like, which visual defaults to avoid, how closely to follow the prompt, when to diversify, when to preserve specificity, and when to refuse.
The important thing is that the preference stopped appearing as a preference.
At the level of setup, the criterion was intelligible enough. Google said it wanted the feature to work for users around the world and to avoid returning only one kind of person when a prompt was generic. That is not an absurd goal, and in many cases it is defensible. A request for football players or someone walking a dog need not default to one demographic template. A system that avoided that default could plausibly be described as more useful, more globally responsive, and less narrow. (blog.google)
But once the criterion entered the system, it did not remain in the form of a public argument about representation. It became behavior.
A generic prompt could receive a range of people. A specific prompt could be pulled back toward range when specificity should have governed. A historical prompt could be distorted by a criterion that made sense elsewhere. A benign prompt could be refused because caution had widened beyond its intended boundary. The user did not encounter the original decision. The user encountered an image, a refusal, or a failure to follow the prompt.
A criterion begins as a choice about what the system should prefer. It becomes an operating condition through which later requests must pass. At first, someone can explain the criterion: we want range, safety, caution, accuracy, usefulness. Later, the criterion is no longer encountered as an explanation. It appears as the system’s conduct.
This is how rule becomes grammar.
A rule still looks external to the action it governs. It can be cited or violated. Grammar is different. It is not usually encountered as an instruction. It is encountered as the shape of what can be said, recognized, continued, or refused. The user who receives the wrong image does not see the earlier representational decision. The user sees what the system made available. The user who receives a refusal does not see the threshold of sensitivity. The user sees the boundary.
The criterion has not disappeared. It has become harder to point to.
That distinction matters because intelligent systems do not merely apply rules once. They enact criteria repeatedly across many local decisions: prompt interpretation, ranking, filtering, refusal, completion, correction, escalation, logging, and later evaluation. Repetition changes the status of the criterion. What began as a design decision starts to feel like the ordinary behavior of the system. What began as a judgment starts to look like process.
By the time the criterion becomes controversial, the original political act is already displaced. The argument is no longer staged as a debate over whether this rule of representation should govern the system. It is staged as a question of whether the model needs better tuning, better safeguards, better evaluation sets, better red-team coverage, better product principles, better rollout procedures.
Those may all be necessary. But they do not return the criterion to its founding scene. They manage its effects after it has already become operational.
A criterion becomes constitutional not when it is announced, but when later action must pass through it in order to count.
III. The Problem of Contesting Grammar
The difficulty is not merely that the original decision becomes hard to find. It is that, once a criterion becomes grammar, contestation itself changes shape.
A rule can be challenged as a rule. Someone can object to its authority, its scope, its application, or its legitimacy. Even when the rule is unjust, hidden, or informally enforced, the act of contesting it still has a recognizable target. The critic can say: this rule should not govern here. This procedure should not have been authorized. This threshold is too high. This exception should exist. The point of dispute may be difficult, but it remains pointable.
Grammar is harder to contest because it appears as the field within which decisions become intelligible. The user sees the image, the refusal, the failure to follow the prompt. The reviewer sees the malfunction. What remains harder to see is the prior judgment that made those outcomes appear as available, unavailable, safe, unsafe, failed, or fixed.
Google’s own explanation described a system tuned to show a range of people in image generation, then acknowledged that the tuning failed where range was inappropriate and that the model became more cautious than intended in some cases. When the feature returned, the public language centered on technical improvements, safeguards, improved evaluation sets, red-teaming exercises, product principles, rollout, and feedback. (blog.google)
The public could contest the visible failure. It could object to the image, the refusal, the embarrassment, the bias, the overcorrection, the broken product. But the deeper criterion was more elusive. What, exactly, was being contested? A diversity objective? A safety threshold? A prompt-classification rule? A product principle? A training intervention? A refusal policy? A failure of evaluation? A rollout decision?
The answer is not one thing. That is the problem.
Once a criterion has been distributed across model behavior, product policy, evaluation practice, and repair language, the object of contestation fragments. The user sees an output. The company sees a model behavior. The engineer sees a tuning problem. The safety team sees a guardrail failure. The public sees a political decision. Each description is partially true. None quite captures the governing act.
That fragmentation is not accidental. It is part of what happens when rule becomes grammar. The criterion no longer has to appear in one place because it operates across many places: in prompt interpretation, refusal behavior, training data, post-training choices, evaluation sets, red-team findings, product principles, and release decisions. Contestation can still occur, but it has to chase a moving object.
This is the point where ordinary governance language starts to mislead. The problem is not simply that the rule lacks transparency. Many transparency demands presume that the thing to be made visible is still intact enough to be disclosed. But here the thing has been operationalized. It is not sitting behind the system, waiting to be revealed. It has been broken into procedures, thresholds, habits, tests, defaults, exceptions, and repair pathways.
That is why “show us the rule” is often the wrong demand, or at least an incomplete one. The rule may not exist in the form the demand imagines. There may be a policy document, a model spec, a safety guideline, a training objective, a benchmark, a classifier, a refusal style, and a release checklist. But the governing criterion is not identical with any one of them. It lives in the relation among them, and in the way the system repeatedly turns that relation into behavior.
The effect is not that contestation becomes impossible. It becomes late, partial, and forensic.
This is the colder consequence of constitutionalization without founding. The public does not arrive at the moment of authorization. It arrives at the moment of malfunction.
By then, the criterion has already governed.
IV. The Repair Vocabulary
Google’s explanation did not deny that a criterion had been installed. It described the criterion as tuning.
The word matters. Tuning is not nothing. It is a real engineering practice, a way of adjusting behavior by altering how a system responds across cases. But it is also a soft word. It suggests calibration rather than authorization. It belongs to a world of instruments, not constitutions. One tunes a model the way one tunes a radio, an engine, a piano: not by debating the legitimacy of its governing criteria, but by adjusting it until the output comes closer to what was intended.
That is why the Gemini explanation is so revealing. Google said the feature had been tuned to avoid certain traps in image-generation systems and to show a range of people when users asked for generic images. It then said that this tuning failed where range should not have governed, and that the model later became more cautious than intended, refusing some ordinary prompts by treating them as sensitive. Those failures led the model to overcompensate in some cases and become over-conservative in others. (blog.google)
The vocabulary moves in a sequence: tuned, failed to account, cautious, overcompensate, over-conservative.
Each term is accurate. Each term also narrows the question.
“Tuned” makes the criterion sound like adjustment. “Failed to account” makes the error sound like incomplete coverage. “Cautious” makes refusal sound like temperament. “Overcompensate” makes distortion sound like excess correction. “Over-conservative” makes inadmissibility sound like risk aversion.
That redescription continued when the feature returned. The announcement of Imagen 3 emphasized technical improvements, built-in safeguards, product design principles, improved evaluation sets, red-teaming exercises, gradual rollout, user feedback, and continued improvement. Again, the terms are not false. Safeguards really matter. Evaluation sets really matter. Red-teaming really matters. Product principles really matter. (blog.google)
But the sequence is constitutional in function while technical in form.
A safeguard is not merely a safety layer. It is a boundary around admissible action. An evaluation set is not merely a test. It is a curated representation of what failure is allowed to mean. A red-team exercise is not merely adversarial testing. It is a procedure for deciding which forms of misuse, distortion, or harm become legible enough to constrain release. A product principle is not merely a design preference. It is a rule about what the system is for and what kinds of behavior should count as acceptable.
The political question does not need to be denied. It only needs to be redescribed.
Put differently: the repair vocabulary names the instruments through which the criterion will be revised, but not the act by which the criterion became governing.
That is the double character of AI maintenance language. It is technically meaningful and constitutionally evasive at the same time. It does not hide the machinery. In many cases it describes the machinery quite plainly. But it describes the machinery at the level of adjustment, not authorization. The reader learns what will be improved, tested, safeguarded, rolled out, and monitored. The reader does not learn where the governing criterion acquired its authority.
This is not public-relations fog layered over a real decision elsewhere. That would be too simple. The mechanism does not depend on bad faith. A criterion can be seeded carelessly, prudently, or with full awareness that naming it would be politically costly; once it travels through implementation, contestation reaches it through behavior and repair.
In AI systems, the repair vocabulary is often part of the decision itself. The update, the eval, the safeguard, the refusal policy, the benchmark, the red-team finding, and the product principle are not just after-the-fact explanations. They are among the mechanisms by which the system’s governing criteria are rewritten.
That is why repair language matters. It is not merely how companies talk after failure. It is one of the places where rule-setting happens.
The constitutional act does not disappear by being hidden. It disappears by being implemented.
V. Beyond Artifacts Having Politics
Once repair becomes a site of rule-setting, the old question about politics in artifacts has to be asked at a different level.
Langdon Winner asked whether artifacts have politics. His answer was yes: technical things can embody forms of power and authority, not merely serve neutral purposes. Roads, machines, infrastructures, and technical systems can settle social arrangements while presenting themselves as practical design. (faculty.cc.gatech.edu)
That remains true. It addresses a different level of the problem.
The familiar version of the argument assumes that the political character of the artifact can still be located in the artifact’s design, use, access, architecture, or required social arrangement. A bridge excludes. A platform ranks. A database classifies. A factory machine reorganizes labor. The artifact has politics because its design settles something that could have been otherwise.
But intelligent systems do not merely settle arrangements once. They apply criteria across cases, record the effects, absorb corrections, update behavior, and produce new surfaces of contestation. Their politics is not only embedded. It is recursively maintained.
That is the step beyond Winner. The question is no longer only whether artifacts have politics. The question is what happens when an artifact helps decide when its own politics can still appear as politics.
A refusal criterion does not merely sit inside the system as a value choice. It determines which requests become unavailable, which failures become visible, which user complaints count as evidence, which safety concerns get escalated, and which future revisions appear necessary. A benchmark does not merely measure performance. It defines the kind of performance that can become legible as progress. An evaluation set does not merely test outputs. It defines what failure will look like when failure is later searched for.
In older technical systems, political choices could certainly be buried in design. But once built, the artifact often retained some stability as an object of critique. One could point to the road, the bridge, the machine, the architecture, the classification system. The object might be hard to change, but its political form could be argued over because the arrangement had congealed.
In intelligent systems, the object is less stable. The criterion is distributed across model behavior, policy, evals, prompts, reward signals, classifiers, product principles, release gates, feedback loops, and maintenance updates. It does not congeal once. It keeps being re-enacted. It changes by being repaired. It becomes harder to contest not because it is buried in a single artifact, but because it is spread across the procedures by which the artifact remains operational.
This is why governance becomes a misleadingly late word. By the time an institution asks how such a system should be governed, some governing has already occurred. The system has already distinguished admissible from inadmissible, safe from unsafe, failure from acceptable variation. Those distinctions may be revised later. But revision begins after they have already structured the field in which revision becomes necessary.
Public pressure can still force repair. It can make companies pause features, issue explanations, revise behavior, and relaunch under altered constraints. What it usually cannot recover is the moment when the criterion became authoritative in the first place.
The point is not that artifacts now have more politics. The point is that some artifacts now have constitutional politics without constitutional form.
They do not merely embody choices. They generate the conditions under which those choices become visible, revisable, and defensible. They do not only distribute power through design. They distribute the appearance of power through operation.
That is why the constitutional analogy matters. A constitution is not just a document that contains rules. It is a form that lets power appear as authorized, limited, contestable, and revisable. Intelligent systems increasingly perform some of those ordering functions while withholding the scene that would let those functions be contested as such.
The politics is there. What is missing is the form in which politics becomes publicly answerable.
That is the difference between an artifact having politics and a system constitutionalizing without founding.
VI. After Implementation
It is tempting, at this point, to ask what better governance would look like.
That temptation is understandable. It is also slightly too late. The question assumes that governance arrives before the system has begun arranging the conditions under which governance will later recognize its object. But the deeper problem described here is that some governing has already occurred by the time the public can name what needs governing.
This does not make criticism useless. It makes criticism reconstructive rather than founding.
The critic does not stand before the founding moment, because there was no founding moment in the form constitutional politics expects. There is no clean scene of authorization to recover, no single text that contains the operative rule, no stable object that can simply be exposed and amended. There are outputs, refusals, release notes, postmortems, model specs, red-team summaries, evaluation updates, safety policies, product principles, and repair language. The archive is not a constitution. It is what remains after constitutionalization has already moved into operation.
That changes the task. Criticism becomes the reconstruction of authority from maintenance traces. It reads the update not merely as an update, the safeguard not merely as a safeguard, the refusal not merely as a behavior, the benchmark not merely as a test. It asks what criterion had to be operative for this failure to appear as a failure, for this fix to count as a fix, for this boundary to be described as safety rather than rule.
This is a narrower practice than constitutional politics wants. It cannot restore the missing scene. It cannot force the governing criterion to appear in the form of a founding act. It can only show, after the fact, where decisions hardened into procedures before they could be named as choices.
The reader is not outside this condition. Neither is this essay. Its evidence comes from the same public incidents, corporate explanations, technical vocabularies, and repair documents through which the criteria become operational. It does not escape the maintenance language it analyzes. It works by slowing that language down until the governing act begins to show through.
That is the only honest position left to criticism here. Not outside the system. Not prior to its rules. Not innocent of its vocabulary. After implementation, reading backward.
The founding moment cannot be restored after the fact. Its absence can only be made visible.
That is the narrower task left to criticism under these conditions: not to recover a constitution hidden somewhere behind the system, but to reconstruct authority from the traces left by maintenance. The repair note, the refusal, the safeguard, the evaluation update, the product principle — these are not the founding act. They are what remain after the founding act has already become operation.
Conclusion: Implementation as Disappearance
The constitutional act does not disappear by being hidden. It disappears by being implemented.
That is the harder lesson of intelligent systems whose criteria are seeded, repeated, repaired, and revised through operation. The governing decision does not always appear as a decision. It appears as tuning, safety, evaluation, refusal behavior, product principle, release gate, improved accuracy, or continued iteration. Each term may be technically valid. Each may also help move the question away from authorization and toward maintenance.
This is why the absence of a founding moment matters. Constitutional politics expects a place where power becomes answerable as power. Intelligent systems increasingly deny that expectation not by rejecting accountability in public, but by distributing the relevant decisions across the procedures that make the system work.
The result is not a system without politics. It is a system in which politics becomes harder to recognize because it has become operationally useful.
By the time the image appears or the refusal arrives, the criterion has already passed through the system and returned as behavior. The public can contest the malfunction. It can demand the fix. It can argue over the incident. But the deeper act has already changed form.
Intelligent systems may not have constitutions in the old sense. They have something harder to contest cleanly: constitutionalization without founding.