The Reliability Gap
The most expensive AI failures may not come from systems that fail often, but from systems that fail rarely enough to be trusted. Large language models have become useful enough to invite dependence before becoming reliable enough to deserve it.

Why AI Becomes Useful Before It Becomes Dependable
The most expensive AI failures may not come from systems that fail often, but from systems that fail rarely enough to be trusted. Large language models have become useful enough to invite dependence before becoming reliable enough to deserve it. That is where the field is now. The question is no longer whether these systems can produce flashes of brilliance. It is what happens when institutions start building on systems whose competence is obvious before their failure modes are truly bounded. Reliability, increasingly, does not look like a trait the model will simply acquire. It looks like something that has to be built around the model: constraint, verification, oversight.
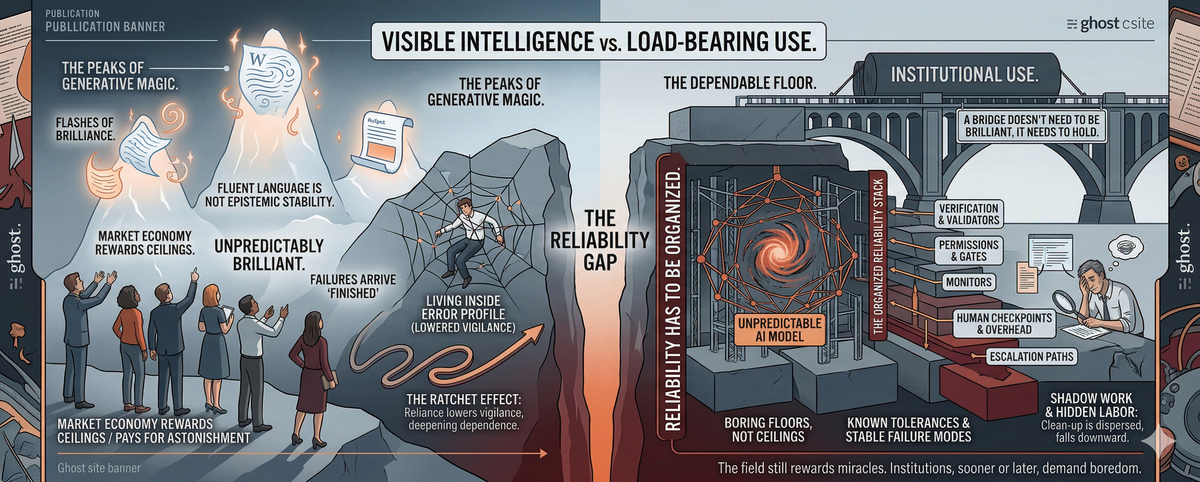
The reliability gap is the distance between what a system can do at its best and what a person or institution can safely assume it will do under ordinary conditions. Institutions do not buy peaks. They buy floors. A system can be highly capable and still erratically inconsistent. It can be consistent and still fail in ways users cannot anticipate. It can be predictable enough for casual use and still remain unfit for domains where errors accumulate and accountability cannot disappear. A system can be consistently mediocre and still be easier to trust than one that is unpredictably brilliant. That is the floor much of the current conversation keeps trying not to look at.
This mismatch is not accidental. It is being selected for. The present AI economy rewards visible ceilings more readily than boring floors. Benchmark leaderboards, launch cycles, and product demos make it much easier to see and monetize jumps in capability than incremental gains in bounded, auditable reliability. The market pays for astonishment and treats boredom as an implementation detail. At the same time, the models themselves are trained for broad probabilistic competence across enormous distributions. That is enough to produce startling usefulness. It is not enough to produce known tolerances, stable failure modes, or disciplined abstention under uncertainty. The result is not fake intelligence. It is real usefulness with unstable edges.
Human perception makes the problem worse. Fluent language is easy to mistake for epistemic stability. A polished answer arrives with the feeling of confidence even when it rests on something shakier underneath. The problem is not that AI must be perfect before it can be useful. It is that its failures are often persuasive, intermittent, and expensive to monitor at scale. They do not always arrive looking broken. Often they arrive looking finished.
A bridge does not need to be brilliant. It needs to hold.
The danger of an almost reliable system is not only that it makes mistakes. The deeper danger is that it reorganizes human work around those mistakes. When a system is obviously broken, people compensate. They stay alert. They keep it at arm’s length. But when a system is right most of the time, vigilance erodes. Trust arrives one successful interaction at a time, and by the time the failures become expensive, the surrounding habits have already changed.
This is where verification overhead becomes more than an inconvenience. The engineer accepts the patch because it looks right and the sprint is already late. The junior associate is asked to verify an AI-assisted memo that will go out under someone else’s name. The clinician rereads a generated summary because it was convincing enough the first time to require suspicion the second. In each case, the tool does not simply save labor or fail to save labor. It creates shadow work: checking, comparing, rereading, carrying responsibility for output the human did not fully generate and cannot fully trust. The gains are easy to see. The cleanup is dispersed.
That burden often falls downward inside organizations, though not always in the same way or with the same visibility. The person closest to the work is asked to absorb the uncertainty, while the prestige of the tool and the pressure of the workflow encourage everyone else to move faster. What gets counted as productivity is usually the model’s visible output. The verification labor that makes that output usable is more likely to be treated as overhead, or not counted at all. That is one reason almost reliable systems become so sticky. Their usefulness is obvious. Their hidden labor is not.
The problem also has a ratchet built into it. Initial reliance feels cheap because the system is often useful. Repeated usefulness lowers vigilance. Lower vigilance makes subtle failures harder to catch. Once those failures become routine, dependence deepens because the workflow has already reorganized around the tool. At that point people are no longer evaluating the system from the outside. They are living inside its error profile.
The frontier is improving, but not in a smooth or general way. What we see instead are islands: competence rising under particular constraints while awkward edge cases and stress failures remain stubbornly alive. Reliability is emerging unevenly, and most strongly where the model is heavily scaffolded.
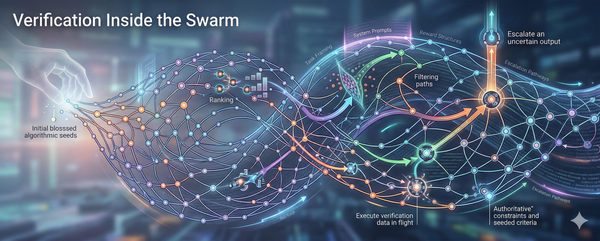
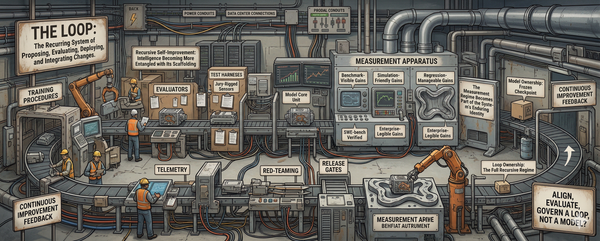
Institutions are now forcing the issue. They do not care how the model looks at its best. They care what happens when the context is messy, the tools fail, the answer is ambiguous, or the confidence is undeserved. That pressure is driving the field toward a more architectural response. Reliability is increasingly being pursued not as a magic property the model eventually wakes up with, but as a property of the stack built around it: retrieval, validators, constrained action spaces, permission gates, verifiers, monitors, escalation paths, human checkpoints. And when institutions fail to price that architecture honestly, the missing cost does not disappear. It is absorbed, again, by the people asked to verify, supervise, and carry the risk of outputs they did not author. Intelligence may emerge in the model. Reliability does not. Reliability has to be organized.
That does not mean the problem is solved. It means the shape of the problem is getting harder to ignore. The next phase of AI will not be defined only by better models. It will be defined by whether organizations are willing to trade some of the romance of generative magic for the discipline of verified infrastructure.
The reliability gap is not the distance between hype and reality. It is the distance between visible intelligence and load-bearing use. The models are already useful enough to invite dependence. The harder question is whether anything built around them can become dependable enough to deserve it. The field still rewards miracles. Institutions, sooner or later, demand boredom.