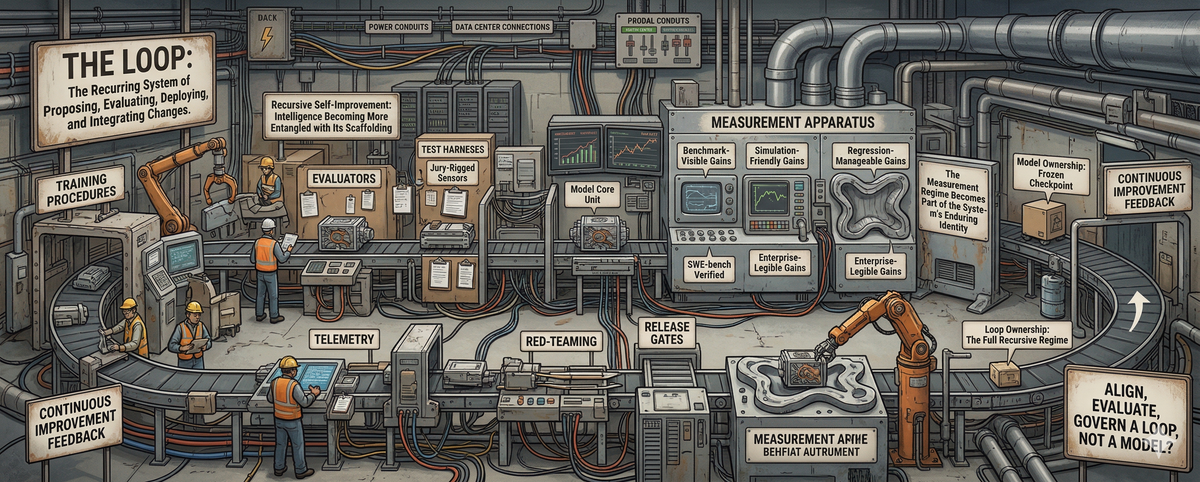
The Loop is the System
The deeper question is whether the surrounding process can recognize that successor as better, distinguish gain from drift, and make the gain stick.

Why recursive self-improvement is less about intelligence escaping constraint than becoming more entangled with it
Recursive self-improvement is usually pictured in a very clean way. A model improves itself, then improves the process that improves it, and after a while the gains begin to compound. It is an appealing picture because it locates the drama inside the model. Intelligence looks self-propelling. The system seems to lift itself by its own cleverness.
But that picture leaves out the part that matters. A proposed change is not the same thing as retained improvement. A system only improves recursively if changes can be evaluated, selected, integrated, deployed, and carried forward across iterations. The glamorous part is not enough. Variation is cheap. Progress is not. Progress requires machinery.
That omission matters because it distorts the unit of analysis. It gets us talking as though the model were the thing that improves, when in practice the model is only one part of a larger arrangement: training procedures, evaluators, test harnesses, tool scaffolds, telemetry, red-teaming, release gates, rollback authority. By the loop, I mean that recurring system: the one that proposes changes, evaluates them, deploys them, observes their effects, and decides what survives into the next iteration. Once improvement becomes continuous, the real question is no longer just whether a model can generate a better successor. The deeper question is whether the surrounding process can recognize that successor as better, distinguish gain from drift, and make the gain stick.
That is where the real shift begins. Once the surrounding machinery becomes continuous and load-bearing, the model is no longer the most relevant thing that persists through improvement. A checkpoint is a snapshot. It may matter enormously in the moment, but it does not explain the continuity of development across iterations. What persists is the organized process that generates revisions, tests them, rejects some, keeps others, and feeds the results back into further change. The model is still real. It is just no longer enough. In a mature recursive regime, the enduring entity is not the artifact at a single moment but the process that keeps transforming it. The model is an episode; the loop is the system.
The Ontological Shift
You can see this, at least in outline, in frontier practice already. Anthropic’s Constitutional AI is one visible example of the broader pattern. It describes a training arrangement built around sampled outputs, self-critiques, revisions, AI-based preference judgments, and reinforcement learning from AI feedback. The point is not that this single technique proves some final ontology. It is that the arrangement makes something visible. The durable asset is not just a frozen checkpoint. It is the recurring organization of critique, evaluation, retraining, and steering that shapes what the next checkpoint becomes.
Anthropic’s publication of Claude’s constitution sharpens the point. The constitution is not just a policy memo sitting next to the model. It is part of the steering apparatus that shapes behavior through training and evaluation. That means the persisting loop includes not just outputs and evaluators, but also the evolving rule-set that helps steer those evaluations in the first place.
The same pattern appears, differently, in frontier reasoning systems. OpenAI’s o1 introduction described models trained to spend more time thinking before they respond, to try different strategies, and to recognize mistakes. Just as important, OpenAI paired that capability language with process language: rigorous testing, Preparedness Framework evaluations, red teaming, government institute access, board-level review. This does not prove some final metaphysical conclusion. It does show something structural. Frontier labs are not just building answer engines. They are building model-plus-evaluation-plus-governance regimes. Even when the public surface still names a model, the thing being accumulated looks more and more like a loop.
What the Loop Can See
A bottleneck is only a brake. It slows a process from the outside. The deeper fact is that the loop can only improve along dimensions it can reliably observe, score, and retain. Infrastructure does not merely constrain recursive self-improvement. It formats it. It helps decide which kinds of gains are legible enough to count as progress.
A loop cannot stabilize around forms of improvement it cannot detect. If a capability gain is real but hard to measure, expensive to verify, ambiguous in value, or difficult to separate from noise, then it will struggle to survive inside a recursive regime. The gains that accumulate will tend to be the ones that fit the measurement apparatus: benchmark-visible gains, simulation-friendly gains, regression-manageable gains, enterprise-legible gains. From the outside, that may still look like self-improvement in the abstract. From inside the loop, it is something more specific. It is adaptation to the available instrumentation. The loop learns in the shape of its own instrumentation.
That can sound abstract until you put a mechanism under it. SWE-bench is useful here because it makes the logic concrete. It evaluates models on real GitHub issues by asking them to generate a patch that resolves the issue, using a reproducible harness to determine whether the patch works. That is already closer to real engineering than toy coding quizzes, which is part of why it mattered. But the important point is not simply that SWE-bench measures coding ability. It is that a loop repeatedly tuned against SWE-bench-style or private agentic evaluations will tend to become fluent at the kinds of software problems those harnesses make legible. The harness is not just standing outside the loop with a clipboard. Over time, it helps define which improvements can be retained as real.
OpenAI’s decision to stop using SWE-bench Verified as a frontier coding metric makes the deeper problem hard to ignore. The benchmark had become increasingly contaminated, and many remaining tasks suffered from flawed test design or problem description. More importantly, apparent gains on the benchmark were increasingly reflecting exposure to benchmark material rather than meaningful gains in real-world software ability. The point is not only that benchmarks can be gamed or saturated. People inside the field already know that. The deeper issue is that once a benchmark becomes load-bearing inside a recursive regime, it stops being a mere scoreboard and starts participating in what the system becomes. The loop may optimize against a distorted target and then carry those distortions forward as if they were progress. SWE-bench does not merely measure the loop. Under recursive pressure, it can help bend the path of improvement away from the capability it was supposed to track.
This is why the bottleneck story is incomplete. The issue is not only that recursive self-improvement may be slower than the more breathless rhetoric suggests. The issue is that it may become very efficient at producing a specific kind of progress: the kind that existing evaluation infrastructure can cheaply register, trust, and propagate. A loop tuned against coding harnesses may get better at patch generation while staying brittle on ambiguous stakeholder demands, inter-team negotiation, or long-horizon maintenance. A loop tuned against narrow safety tests may get better at passing those tests while leaving other forms of fragility harder to see. That does not mean the gains are fake. It means they arrive already shaped by the instrumentation that made them visible.
From Model Ownership to Loop Ownership
Once you see that, the power question changes too. If the loop is the real system, then strategic advantage shifts away from model possession alone and toward control over the machinery that makes gains durable. The critical asset is no longer just a strong model. It is a thick recursive regime: evaluators, telemetry, simulation environments, tool scaffolds, rollback history, deployment pathways, and the authority to decide what counts as progress. Whoever controls that retention machinery controls not only the speed of improvement but its direction and definition.
In practice, these regimes are often far less tidy than they appear from outside. They are patchworks of dashboards, ad hoc review gates, contested metrics, brittle handoffs, and institutional improvisation. But messy loops still select what survives. Disorder does not abolish the structure. It just makes the structure more political.
That is one reason the current infrastructure race matters, though not in the shallow sense of “more GPUs equals victory.” The physical layer matters: power, datacenters, networking, cooling, land, grid access. But the same frontier labs are also investing heavily in internal evaluation, governance, and release machinery. So the race is two-sided: not just more chips, but tighter control over the private evaluation, deployment, and rollback systems that define what counts as progress inside the loop. The push for physical infrastructure sovereignty and the push for loop sovereignty are really two faces of the same strategic reality. Durable advantage belongs to whoever can both supply the process and define its standards of retention.
Seen this way, the moat moves. It moves from model ownership to loop ownership. Public access to weights may still matter. Benchmark scores may still matter. But if the most valuable part of recursive improvement lives in private telemetry, internal eval suites, deployment feedback, and retention authority, then the decisive advantage may belong less to whoever possesses a model artifact than to whoever controls the recursive regime in which artifacts are selected, corrected, and made durable. The unit that compounds is no longer simply the model. It is the loop surrounding it.
That shift should make us more precise about what is actually being aligned, evaluated, and governed. Much of the public conversation still speaks as though the object of concern were a model with a stable identity: this model is safer, that model is more capable, this release is more aligned. But if improvement is increasingly recursive, and if the enduring system is increasingly the loop rather than the checkpoint, then those categories may be aimed at the wrong target. The challenge is no longer just how to evaluate a model. It is how to evaluate an arrangement that continuously transforms models through instrumentation, feedback, and retention.
The fantasy of recursive self-improvement is that intelligence escapes its scaffolding. The more plausible reality is almost the reverse. As improvement becomes continuous, intelligence becomes more deeply entangled with the infrastructures that can observe it, test it, trust it, and carry it forward. That does not make recursive self-improvement unreal. It makes it more concrete. The decisive question is no longer only how smart the model is. It is what kind of loop surrounds it, what that loop can recognize as progress, and who controls the machinery by which progress is made real. And if that is the right unit, then the next question opens wider than the essay’s starting picture ever allowed: what would it mean to align, evaluate, or govern a loop rather than a model?
FAQs
What does it mean that “the loop is the system” in recursive self-improvement?
The enduring entity is no longer a single model checkpoint but the organized process of revision, evaluation, retention, and redeployment that compounds across iterations.
How does instrumentation shape recursive AI improvement?
A loop can only stabilize around gains it can reliably observe and score. Over time it drifts toward benchmark-visible, simulation-friendly, or enterprise-legible progress, even when those are not identical with deeper capability.
Why does loop ownership matter more than model ownership?
Whoever controls the private evaluation suites, telemetry, rollback systems, and governance machinery controls both the speed and the direction of improvement.